Python并发编程(一)
Python解释器由于设计时有GIL全局锁,导致了多线程无法利用多核。多线程的并发在Python中就是一个美丽的梦。 – 廖雪峰
GIL锁 (Global Interpreter Lock)

Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁(Global Interpreter Lock),任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
所以,Python 的线程更适用于处理IO密集型的阻塞操作(比如等待I/O、等待从数据库获取数据等等),而不是需要多处理器并行的计算密集型任务(即:CPU密集型)。
GIL是Python解释器设计的历史遗留问题,通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器🤪 。
所以,在Python中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过这样就失去了Python简单易用的特点。
不过,也不用过于担心,Python虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务😕 。多个Python进程有各自独立的GIL锁,互不影响。
WHY: python使用引用计数器进行管理对象, 引用数为0释放对象, 简化python对共享资源的管理.
总结: GIL锁是Python解释器的”设计缺陷”,无法实现多核任务, 且短期内改不掉, 但是可以通过多进程实现多核任务.
多线程下IO密集型和cpu密集型对比总结
1. CPU密集型(CPU-bound)
一个计算为主的程序。多线程跑的时候,可以充分利用起所有的cpu核心,比如说4个核心的cpu,开4个线程的时候,可以同时跑4个线程的运算任务,此时是最大效率。 但是如果线程远远超出cpu核心数量反而会使得任务效率下降,因为频繁的切换线程也是要消耗时间的。 因此对于cpu密集型的任务来说,线程数等于cpu数是最好的了。
比如: 压缩解压缩, 加密解密, 正则表达式搜索等
2. IO密集型(I/O-bound)
如果是一个磁盘或网络为主的程序(IO密集型)。一个线程处在IO等待/阻塞的时候,另一个线程还可以在CPU里面跑,有时候CPU闲着没事干,所有的线程都在等着IO,这时候他们就是同时的了,而单线程的话此时还是在一个一个等待的。我们都知道IO的速度比起CPU来是慢到令人发指的。所以开多线程,比方说多线程网络传输,多线程往不同的目录写文件,等等。此时线程数等于IO任务数是最佳的。
比如: 文件处理, http请求, 数据库读写等
多线程编程
优点:
- 相比于进程, 更轻量, 占用资源少
缺点:
- 相比进程: 多线程只能并发执行, 不能利用多CPU (GIL)
- 相比协程: 启用数目有限制, 占用内存资源, 有线程切换开销
适用于:
- IO密集型计算, 同时运行的任务数目要求不多
普通多线程编程
使用threading模块创建Thread实例, 然后调用start()开始执行
import threading, time
def do_something(i):
print(f"Start doing {i}")
time.sleep(2)
print(f"End doing {i}")
return True
def main():
threads = []
for i in range(10):
this_threading = threading.Thread(target=do_some_thing, args=(i, ))
# 调用`start()`开始执行
this_threading.start()
threads.append(this_threading)
print("___主线程开始🔛___")
# 调用`thread.join()`的作用是确保子线程执行完毕后才能执行下一个线程
for thread in threads:
thread.join()
print("___主线程结束🔚___")
if __name__ == '__main__':
main()
加锁保证线程安全
“当多个线程同时执行
lock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用try...finally来确保锁一定会被释放。”锁的作用是确保某段关键代码只能由一个线程从头到尾完整地执行,坏处当然也很多,首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。其次,由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。
- 方案1: try-finally 模式
import threading, time
lock = threading.Lock()
def do_something(i):
lock.acquire()
try:
print(f"Start doing {i}")
time.sleep(2)
print(f"End doing {i}")
finally:
lock.release()
return True
def main():
threads = []
for i in range(10):
this_threading = threading.Thread(target=do_something, args=(i, ))
# 调用`start()`开始执行
this_threading.start()
threads.append(this_threading)
print("___主线程开始🔛___")
# 调用`thread.join()`的作用是确保子线程执行完毕后才能执行下一个线程
for thread in threads:
thread.join()
print("___主线程结束🔚___")
if __name__ == '__main__':
main()
- 方案2: with模式 推荐
import threading, time
lock = threading.Lock()
def do_something(i):
with lock:
print(f"Start doing {i}")
time.sleep(2)
print(f"End doing {i}")
return True
def main():
threads = []
for i in range(10):
this_threading = threading.Thread(target=do_something, args=(i, ))
# 调用`start()`开始执行
this_threading.start()
threads.append(this_threading)
print("___主线程开始🔛___")
# 调用`thread.join()`的作用是确保子线程执行完毕后才能执行下一个线程
for thread in threads:
thread.join()
print("___主线程结束🔚___")
if __name__ == '__main__':
main()
线程池和进程池 For Python3.2+
从
Python3.2开始,标准库为我们提供了concurrent.futures模块,它提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,实现了对threading和multiprocessing的进一步抽象
线程池作用:
- 提升性能: 因为减去了大量新建, 终止线程的开销, 重用了线程资源
- 适用场景: 使用处理突发大量请求或者需要大量线程完成任务, 实际处理时间较短
- 防御功能: 能有效避免系统因为创建线程过多,而导致系统负荷过大响应变慢等问题
- 代码优势: 语法比自己新建线程执行线程更加简洁
- 可以帮我们自动调度线程
- 主线程可以获取某一个线程(或者任务的)的状态,以及返回值。
- 当一个线程完成的时候,主线程能够立即知道。
- 让多线程和多进程的编码接口一致。
1. ThreadPoolExecutor
- 第一种, 使用
map
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor() as pool:
# map入参与结果顺序是一致的
results = pool.map(func, agr_list)
for result in results:
...
- 第二种, 使用
submit
from concurrent.futures import ThreadPoolExecutor, as_completed
with ThreadPoolExecutor() as pool:
futures = [pool.submit(func, agr) for agr in agr_list]
# 1. 不用as_completed, 顺序是固定的
for future in futures:
result = future.result()
# 2. 使用as_completed
# as_completed特点: 顺序是不固定的
for future in as_completed(futures):
result = future.result()
多进程(multiprocessing)
- 优点: 可以利用多核CPU并行运算
- 缺点: 占用资源多, 可启动数目比线程少
- 适用于: CPU密集型计算
总结:

多协程(Coroutine)
核心原理:
- 用一个超级循环(while True)
- 配合IO多路复用原理(IO时CPU可以干其他事情)
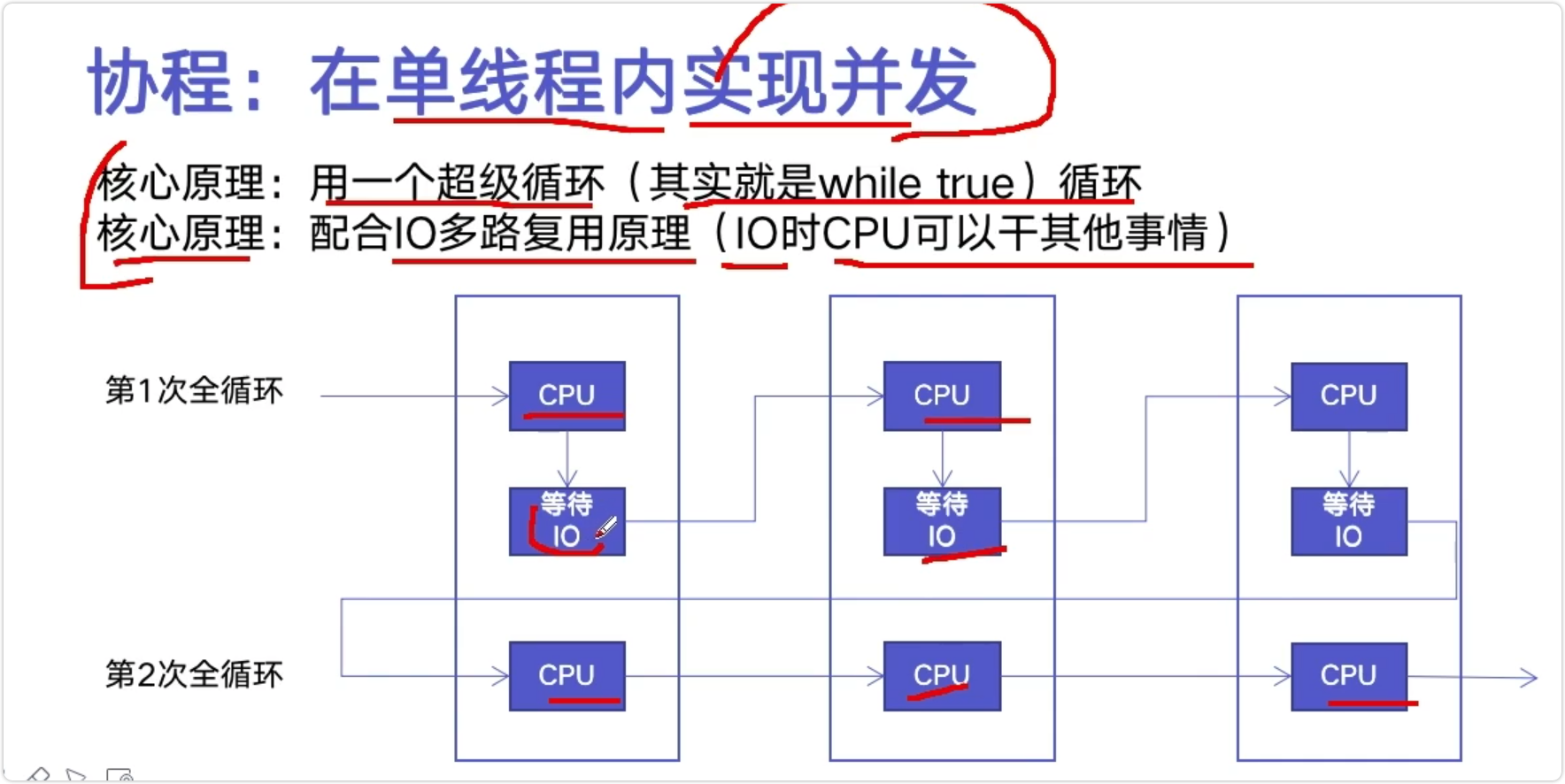
子程序调用是通过栈实现的,一个线程就是执行一个子程序。
子程序调用总是一个入口,一次返回,调用顺序是明确的。而协程的调用和子程序不同。
协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
- 优点: 内存开销最少, 启动协程数量最多
- 缺点: 支持的库有限, 比如:aiohttp, 代码实现复杂
- 适用于: IO密集型计算, 需要超多任务运行, 但需要有现成库支持的场景
import asyncio
# 获取事件循环 至尊循环 :)
loop = asyncio.get_event_loop()
# 定义协程
async def myfunc(url):
# get_url里面是IO密集型计算
await get_url(url)
# 创建task列表
tasks = [loop.create_task(myfunc(url) for url in urls)]
# 执行爬虫事件列表
loop.run_util_complete(asyncio.wait(tasks))
使用信号量(Semaphore)控制协程并发度
信号量是一个同步对象, 用于包吃0到最大值之间的一个技术值.等待-1, 释放+1, 大于0为signaled状态, 等于0为nosignaled状态
第一种, 使用with 推荐
sem = asyncio.Semaphore(10)
asyncio with sem:
...
第二种, 使用try…finally
sem = asyncio.Semaphore(10)
await sem.aquire()
try:
...
finally:
sem.release()
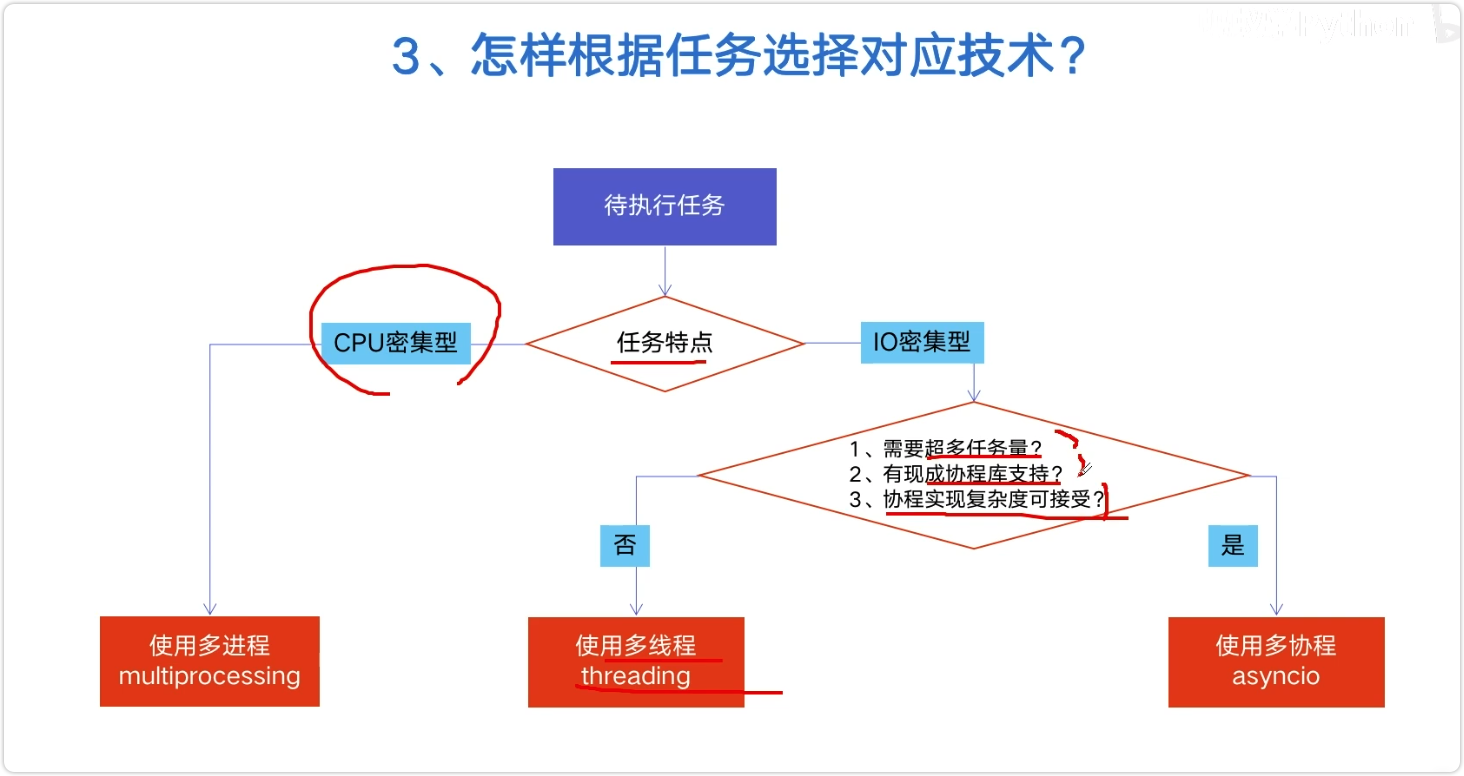
根据任务选择对应技术
参考链接:
- 廖雪峰官方网站: https://www.liaoxuefeng.com/wiki/1016959663602400/1017968846697824
- 简书: https://www.jianshu.com/p/b9b3d66aa0be
- B站: https://www.bilibili.com/video/BV1bK411A7tV?p=2&spm_id_from=pageDriver
- 理解GIL: http://www.dabeaz.com/python/UnderstandingGIL.pdf