ELK笔记
IT部门使用ELK场景
- 汇聚后统一存储,可以按需查询做
- troubleshooting、
- 审计、
- 数据分析
抓取日志方式
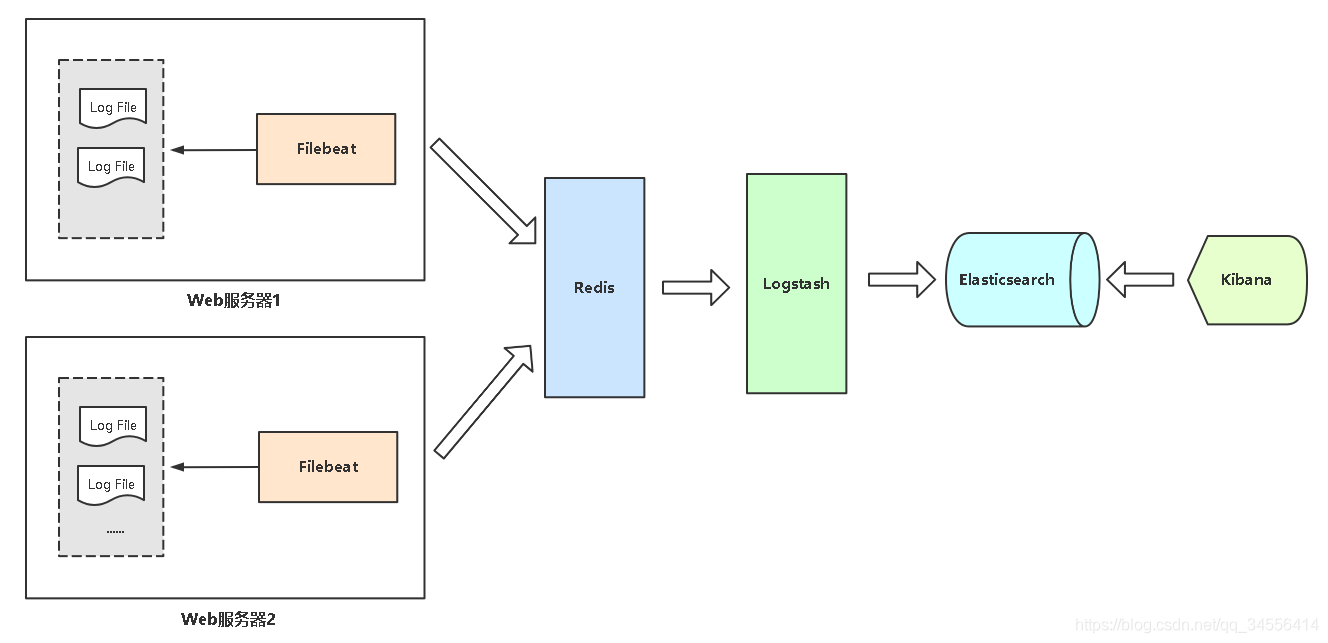
抓取方式,还是要看日志类型, 通常是下图方式
ELK有何优势?
-
强大的搜索功能,elasticsearch可以以分布式搜索的方式快速检索,而且支持DSL的语法来进行搜索,简单的说,就是通过类似配置的语言,快速筛选数据。
-
完美的展示功能,可以展示非常详细的图表信息,而且可以定制展示内容,将数据可视化发挥的淋漓尽致。
-
分布式功能,能够解决大型集群运维工作很多问题,包括监控、预警、日志收集解析等。
ELK一般用来做啥?
ELK组件在海量日志系统的运维中,可用于解决:
-
分布式日志数据集中式查询和管理
-
系统监控,包含系统硬件和应用各个组件的监控
-
故障排查
-
安全信息和事件管理
-
报表功能
ELK组件在大数据运维系统中,主要可解决的问题如下:
-
日志查询,问题排查,上线检查
-
服务器监控,应用监控,错误报警,Bug管理
-
性能分析,用户行为分析,安全漏洞分析,时间管理
elasticsearch 创建index 原则
mapping部分
- type名字:一般来讲,推荐一个index对应一个type,若有多个type,则所有的type的字段大部分应该是相同的。若全部不同,推荐将type设置为index的名字,分成多个index,防止由于文档字段稀疏导致浪费存储。
- 字段名称包含id,推荐用keyword类型,若业务能确认一定是字符串类型,则可以用long型
- 时间戳类型,推荐为long型,方便业务访问,或者date类型,方便kibana和grafana访问。
- status或者type字段,推荐用integer类型,便于枚举
- content字段,推荐确认对应的分词器,设置为text类型,不推荐用keyword。特别是字段很长的情况。
- 聚合类字段推荐设置成keyword,即使是数字类型也需要这样设置,强制将字段的数据组织成倒排索引而非kd-tree提升聚合查询速度。
设置部分
- refresh_interval:该设置主要是每隔多久刷新数据,可以让刚刚写入的数据被查到。若写入数据量较大或者业务对于变更后及时查到的要求不高,则可以设置时间大一些。推荐一些粗糙的准则,若一天的写入能超过100g的数据量,则建议至少设置为10s,500g设置为60s,1T以上设置为120s。具体的以当时集群硬件配置和所有index读取写入的情况而定。
- number_of_shards和number_of_replicas:主分片数和副本分片数,推荐直接设置为12,副本分片数设置为1。具体可以参考文章:https://blog.csdn.net/tanruixing/article/details/87883896 慢日志设置:建议读取写入根据业务访问情况进行设置,唯一需要注意的是不要设置过小,则可能会将磁盘打满,甚至影响数据存储。强烈推荐必须设置,方便后续观察业务使用情况。